
Generative AI has seen an unprecedented surge in the market, and it’s truly remarkable to witness the rapid advancements in technology. Just 11 months since the launch of ChatGPT, we’ve made tremendous progress. What’s particularly fascinating is the swift adoption of generative AI in the open-source community, resulting in the emergence of numerous Large Language Models (LLMs). These open-source LLMs are rapidly narrowing the gap between themselves and commercial counterparts like ChatGPT and Bard (source: https://www.semianalysis.com/p/google-we-have-no-moat-and-neither).
Among the open-source LLMs, two have captured my attention: Llama 2 and CodeLlama. What sets them apart is their accessibility, especially for users like me who can download and run their smaller models (e.g., 7B or 13B) on a CPU-only laptop. Admittedly, my gaming laptop boasts impressive specs, but it’s equipped with an AMD GPU, lacking CUDA support. While there are potential workarounds like DirectML and WSL, I chose not to delve into those complexities. Instead, I opted to work with my current setup, featuring 16 GB of RAM.
However, this decision came with limitations. It ruled out the possibility of using the base models of Llama, even the 7B variant, which alone would demand a minimum of 28 GB of RAM — without factoring in gradients and optimizer states, which would substantially increase memory requirements. In light of these constraints, I found a suitable solution by downloading “The Blokes” 4-bit Quantized model from Hugging Face, which met my development needs effectively.
Simultaneously, I am interested in the concept of “Retrieval Augmented Generation” (RAG) and how enterprises can harness this approach to extract information from backend data stores or APIs. For example, when working with CodeLlama, we can furnish the LLM with table schemas and ask questions in natural language, prompting it to generate the necessary SQL script for retrieving the desired information. To enhance this process, we can employ LangChain for multiple purposes: calling upon the LLM, executing the SQL query against a database, retrieving the results, and then feeding them back into the LLM to produce the final output. What’s particularly promising is the synergy between open-source LLMs and this approach. Enterprises can now leverage their own large language models without concerns about sharing sensitive company data with commercial LLM providers like OpenAI. This opens up exciting possibilities for businesses to maximize the value of their data in a secure and efficient manner.
In this blog post, I will walk you through a specific scenario in which I run CodeLlama on my local setup. I’ll demonstrate the integration of LangChain to interact with the LLM and execute a query against a MySQL Sakila database. My primary focus will be on showcasing the effective use of the Few Shot Prompting technique to train the LLM, enabling it to deliver the desired results we are seeking.
The Scenario — Interacting with a MySQL Database Using Natural Language
Before we delve into the code, let’s discuss the scenario at hand. Our objective is to engage with the Large Language Model (LLM) in a natural language context, wherein the LLM generates queries based on the questions we pose and subsequently executes these queries using chains. In this specific example, we have chosen to work with the MySQL database, specifically the Sakila database.
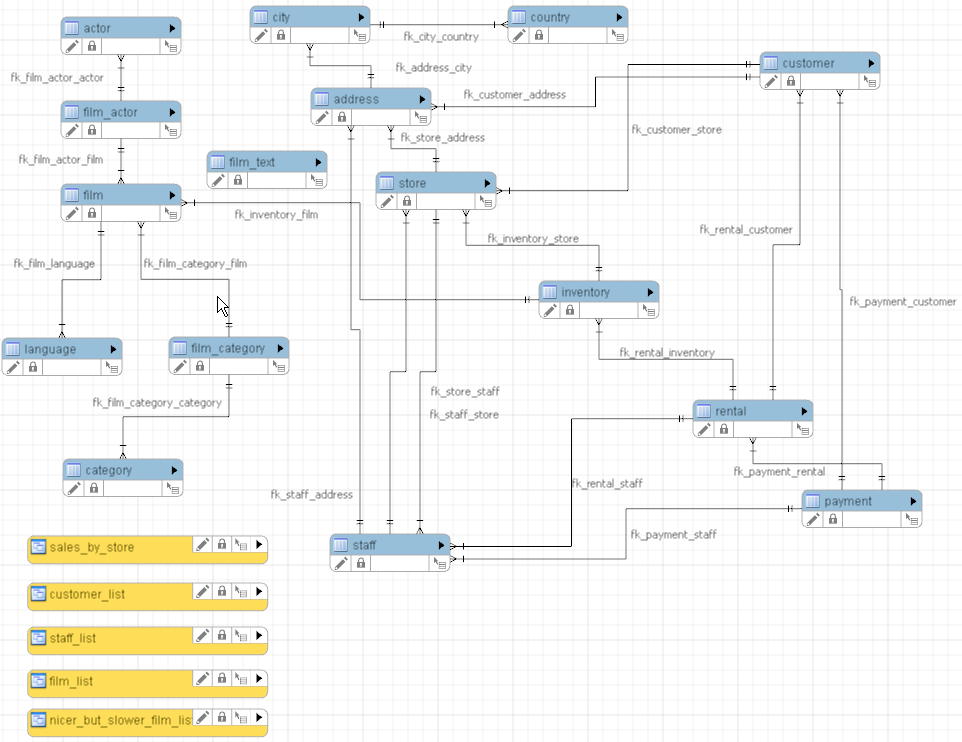
While the Sakila database may be relatively small, it presents sufficient complexity for our purposes. We anticipate the need to craft queries that span multiple tables within a single SQL statement to extract the relevant information we seek. To provide a visual representation of the database’s structure, here’s an ER Diagram sourced directly from MySQL. You can see multiple interrelations across the various tables within the database.
The Prerequisites — Setting Up the Environment and Installing Required Packages
If you wish to access the code and run it on your local system, you can find it on GitHub at https://github.com/yernenip/CodeLlama-LangChain-MySql. I have also added instructions for setting up and executing the code in the GitHub repository. Here are a few essential things to consider before you begin:
- Memory Requirements: Initially, I intended to work with 16 GB of RAM, as mentioned earlier in this post. However, I quickly realized that this allocation was insufficient. Windows itself consumes a significant portion of memory, and running a Docker container further reduces available resources. While I did manage to execute the code with 16 GB of RAM during my initial tests, the process was painfully slow, and at times, it terminated prematurely. To overcome this, I upgraded my system to a total of 24 GB of RAM, providing a more reliable, if not faster, environment.
- Setup Instructions: Once you’ve ensured your hardware meets the necessary specifications, I recommend following the instructions outlined in the GitHub link provided above. This will help you set up your Docker container (including MySQL with the Sakila database), install Jupyter if you plan to use it locally, and install the required Python packages.
By addressing these prerequisites, you’ll be well-prepared to proceed with the code implementation and exploration of CodeLlama and LangChain in your local environment.
Zero shot prompting
Initialization
Let’s now dive into the code. The initial step involves downloading the quantized LLM model and configuring it with a context length of 10,000. While this context length might seem excessive and could potentially slow down the model due to processing a vast amount of context, it’s necessary for querying the database. We need to provide schemas for all the tables and examples for few-shot prompting. I recommend experimenting with the length and other parameters mentioned in the configuration based on your specific use case.
Additionally, I’m explicitly downloading the GGUF format, a newly introduced format by the llama.cpp team, considered a replacement for the GGML format.
import langchain
from langchain.llms import CTransformers
import time
config = {'max_new_tokens': 256, 'repetition_penalty': 1.1, 'temperature': 0, 'context_length': 10000}
#https://github.com/marella/ctransformers#config For config of CTransformers
llm = CTransformers(model="TheBloke/CodeLlama-7B-Instruct-GGUF",
model_file="codellama-7b-instruct.Q4_K_M.gguf",config=config, verbose=True)
Please be patient as the model download may take several minutes, given its size of approximately 3.5 GB. Allow the download to complete before proceeding.
Connecting to database and fetching schema info
Once the model is downloaded, we can establish a database connection using LangChain’s wrapper on SQLAlchemy called “SQLDatabase.” We can then retrieve and print out the table information.
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
langchain.verbose = True
db = SQLDatabase.from_uri('mysql://dbuser:dbpwd@localhost:3306/sakila',
#include_tables=['customer', 'address', 'city', 'country'], # include only the tables you want to query. Reduces tokens.
sample_rows_in_table_info=3
)
print(db.table_info)
This table information is crucial as we will pass it along with our prompt using LangChain’s database chain.
With the LLM and the database connection in place, we can now prompt the LLM with a simple question. I’m using “verbose” to examine additional details and the generated prompt.
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True, return_sql=False, use_query_checker=True)
db_chain.run("How many customers are from district California?")
LangChain’s default prompt template is comprehensive, providing valuable information to the LLM. Unfortunately, due to space constraints, I’m unable to share the entire prompt here. However, I’ve included a small snippet of the screenshot below. Please feel free to run it yourself to examine the prompt’s details.
Vanilla Prompt Example
After the code has finished executing, here is the final output.
Question: How many customers are from district California?
SQLQuery:SELECT COUNT(*) AS `Number of Customers` FROM customer WHERE address_id IN (SELECT address_id FROM address WHERE district = 'California');
SQLResult: [(9,)]
Answer:
> Finished chain.
9
As you can see, CodeLlama generates a SQL query using subqueries. While subqueries are perfectly valid (and sometimes preferred), I have a preference for using JOINs in this context. Additionally, I’ve noticed another issue: when I asked questions that required more complex queries, CodeLlama didn’t provide a query in response. This could potentially be attributed to the 7B version I am using. However, let’s explore if we can address this by employing few-shot prompting.
Few shot prompting
Setting up the example prompts
Let’s begin by preparing an array of examples, each containing the input prompt, the expected SQL query, the result, and the final answer. We will use these examples to create a template for prompting the LLM, using the PromptTemplate provided by LangChain.
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"input": "How many customers are from district California?",
"sql_cmd": "SELECT COUNT(*) FROM customer cu JOIN address ad ON cu.address_id = ad.address_id \
WHERE ad.district = 'California';",
"result": "[(9,)]",
"answer": "There are 9 customers from California",
},
{
"input": "How many customers are from city San Bernardino?",
"sql_cmd": "SELECT COUNT(*) FROM customer cu JOIN address ad ON cu.address_id = ad.address_id \
JOIN city ci ON ad.city_id = ci.city_id WHERE ci.city = 'San Bernardino';",
"result": "[(1,)]",
"answer": "There is 1 customer from San Bernardino",
},
{
"input": "How many customers are from country United States?",
"sql_cmd": "SELECT COUNT(*) FROM customer cu JOIN address ad ON cu.address_id = ad.address_id \
JOIN city ci ON ad.city_id = ci.city_id JOIN country co ON ci.country_id = co.country_id \
WHERE co.country = 'United States';",
"result": "[(36,)]",
"answer": "There are 36 customers from United States",
},
]
example_prompt = PromptTemplate(
input_variables=["input", "sql_cmd", "result", "answer",],
template="\nQuestion: {input}\nSQLQuery: {sql_cmd}\nSQLResult: {result}\nAnswer: {answer}",
)
Vectorizing the examples and using an example selector
Next, we will convert our examples into vector form using sentence transformers and employ a semantic similarity example selector. While vectorization is not strictly necessary, it’s preferred as it transforms our sentences into embeddings, capturing the meaning and context of sentences. This enables LLMs to leverage semantic information, resulting in better-generated responses.
from langchain.prompts import SemanticSimilarityExampleSelector
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
embeddings = HuggingFaceEmbeddings()
to_vectorize = [" ".join(example.values()) for example in examples]
vectorstore = Chroma.from_texts(to_vectorize, embeddings, metadatas=examples)
example_selector = SemanticSimilarityExampleSelector(
vectorstore=vectorstore,
k=1,
)
I am using Chroma DB here which is a vector store and can run in-memory in a python or Jupyter notebook.
Setting up the few shot prompt
Now, let’s configure the few-shot prompt variable that we’ll be passing to the large language model.
from langchain.prompts import FewShotPromptTemplate
from langchain.chains.sql_database.prompt import PROMPT_SUFFIX, _mysql_prompt
#print(PROMPT_SUFFIX)
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix=_mysql_prompt,
suffix=PROMPT_SUFFIX,
input_variables=["input", "table_info", "top_k"], #These variables are used in the prefix and suffix
)
The _mysql_prompt and PROMPT_SUFFIX variables contain additional prompt text that provides instructions to give more context to the LLM. They also include the input variables.
Calling the LLM with few shot prompting
Finally, let’s prompt the LLM using the few-shot prompt and examine the result. My question differs slightly from the example; I replaced “United States” with “Canada.”
local_chain = SQLDatabaseChain.from_llm(llm, db, prompt=few_shot_prompt, use_query_checker=True,
verbose=True, return_sql=False,)
local_chain.run("How many customers are from country Canada?")
Here’s a snippet of what the prompt looks like. You can see that the example for “United States” was selected.
Prompt with Examples
And here is the output.
Question: How many customers are from country Canada?
SQLQuery:SELECT COUNT(*) FROM customer cu JOIN address ad ON cu.address_id = ad.address_id JOIN city ci ON ad.city_id = ci.city_id JOIN country co ON ci.country_id = co.country_id WHERE co.country = 'Canada';
SQLResult: [(5,)]
Answer:
> Finished chain.
There are 5 customers from Canada
> Finished chain.
I also wanted to assess if the few-shot prompting has improved context for the LLM. I posed a different question unrelated to the tables mentioned in my example prompts to see how the LLM responds.
I prompted the LLM with the following question:
local_chain.run("Which actor has appeared in the most films?")
#expected output
'''
select actor.actor_id, actor.first_name, actor.last_name, count(actor_id) as film_count
from actor join film_actor using (actor_id) group by actor_id order by film_count desc
limit 1;
'''
To my delight, the LLM provided an answer very close to the expected output shown above. Here is the output for reference.
Question: Which actor has appeared in the most films?
SQLQuery:SELECT a.actor_id, a.first_name, a.last_name, COUNT(*) AS num_films FROM actor a JOIN film_actor fa ON a.actor_id = fa.actor_id GROUP BY a.actor_id ORDER BY num_films DESC LIMIT 1;
SQLResult: [(107, 'GINA', 'DEGENERES', 42)]
Answer:
> Finished chain.
Gina DeGeneres has appeared in the most films (42).
> Finished chain.
Conclusion
The rapid advancements in AI, especially with open-source tools like Llama and CodeLlama, are changing how we talk to databases using everyday language. The combination of LangChain and Few Shot Prompting makes it easier for us to ask complex questions and get meaningful answers.
As we explored CodeLlama and LangChain, we saw how AI can help us get insights from data while keeping our information safe. Businesses can now use big AI models without sharing sensitive data, which is a big deal.
This journey shows us that AI can make data tasks simpler and more accessible. Whether it’s asking database questions, finding specific info, or answering tricky queries, open-source AI tools and clever techniques are making it easier for businesses to make the most of their data.