
Introduction
Are you looking to accelerate your backend development process through code generation automation? In this blog post, we will explore how ChatGPT can help expedite your development workflow. We will focus on a specific scenario related to ecommerce and delve into the details of creating backend services using FastAPI and PostgreSQL. Additionally, we’ll cover the deployment of the database and APIs to local Docker containers.
You can find the GitHub repository for this blog post at the following location.
https://github.com/yernenip/GPT-FastAPI-PostgreSQL
Technology Selection
Choosing the right technology stack for this exercise proved to be a challenging task. To ensure rapid development and integration, I considered several key criteria:
- Familiarity: It was important to select a technology stack that I was comfortable working with.
- Understandability: I sought a stack that allowed easy comprehension of generated code and enabled the application of fundamental principles like normalization and general design principles.
- Cloud Native: Since deploying and testing on a docker container was essential, I opted for a cloud-native stack.
- Scalability: Anticipating future scalability requirements, I prioritized a technology stack that could easily accommodate growth.
With these principles in mind, I chose PostgreSQL as the backend database (due to my familiarity with MS SQL Server), Psycopg3 for data access, and FastAPI as the backend REST API. FastAPI, known for its ease of use, cloud-native nature, scalability, and compatibility with Python code, also provides out-of-the-box features for Swagger UI and ReDoc, which I found extremely useful. Here is a screenshot of what my api’s look like in both the user interfaces. I love it!
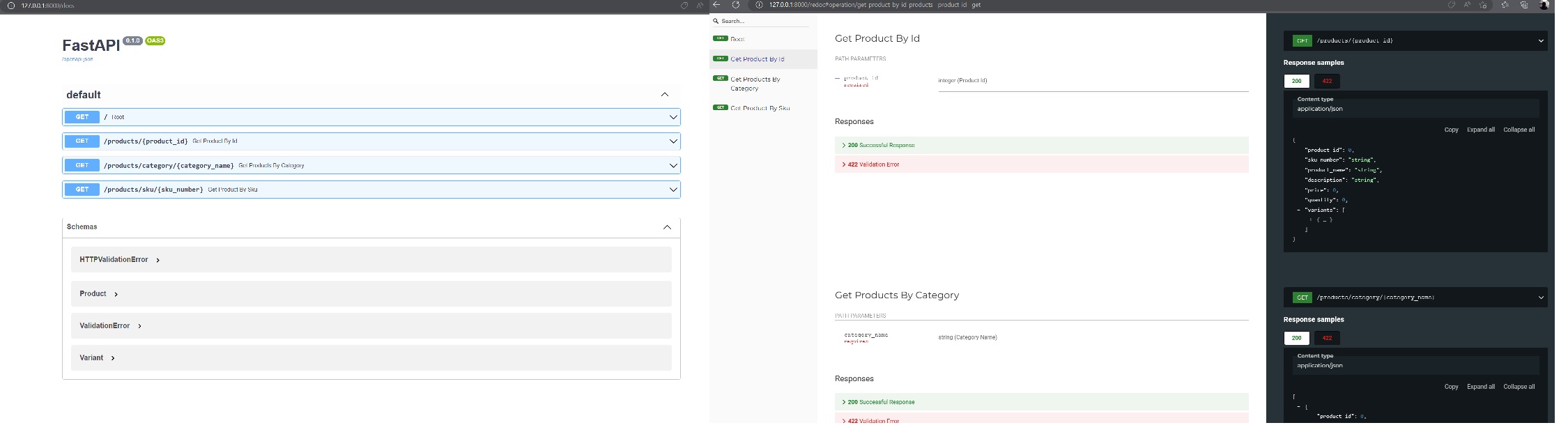
Scenario: Building Backend Services for an Ecommerce Application
In our scenario, we aim to develop backend services for an ecommerce application that sells physical goods. These services will allow consuming applications to perform product lookup based on various criteria, such as product, SKU, and categories. While we’ll focus on a limited number of APIs for the purpose of this blog post, the objective remains leveraging ChatGPT in software engineering. To help visualize the system design, refer to the system diagram below:
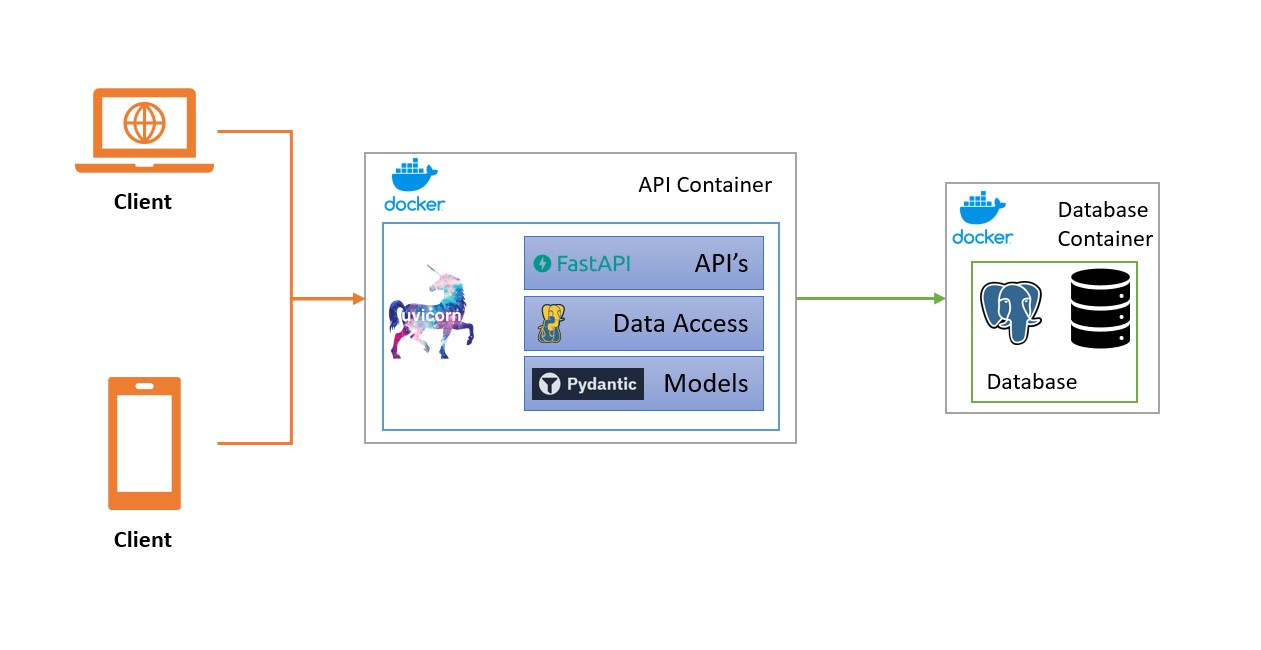
A Note about Prompts
Before proceeding, it’s important to note that the prompts shared below were run multiple times, resulting in slightly varying outputs each time. To provide more details, I made additional tweaks to the prompts. It’s also worth mentioning that I directly used ChatGPT to generate code instead of using the API. Although the code could have been written manually, I opted for generating it using the interface this time.
Engineering the Backend Database in PostgreSQL
To create the backend database, I used the following prompt:
Your task is to generate SQL scripts for postgreSQL for an ecommerce database.
The scenarios are shared below delimted by three stars.
Here are some rules to follow
1. The database should be named "CommerceDB".
2. Before creating any SQL objects, ensure they do not already exist to handle errors better.
3. Verify that the SQL object does not exist before creating it for better error handling.
4. Each primary key fields should have auto-increment enabled, starting from a seed value of 100.
***
Products can be uniquely identified by a product id or a SKU Number.
Products can belong to one or more categories.
Products can have multiple variants, such as size and color, but there could be other variants as well.
Customers can place orders for any number of items.
An order can contain one or more items.
An order should have order amount, shipping amount, tax amount and total.
Once an order is shipped, it can be tracked via a shipment.
***
ChatGPT then generated SQL scripts. You can find the scripts on the GitHub repository.
For illustrative purposes, I transformed these scripts into an Entity Relationship Diagram (ERD), as shown below:
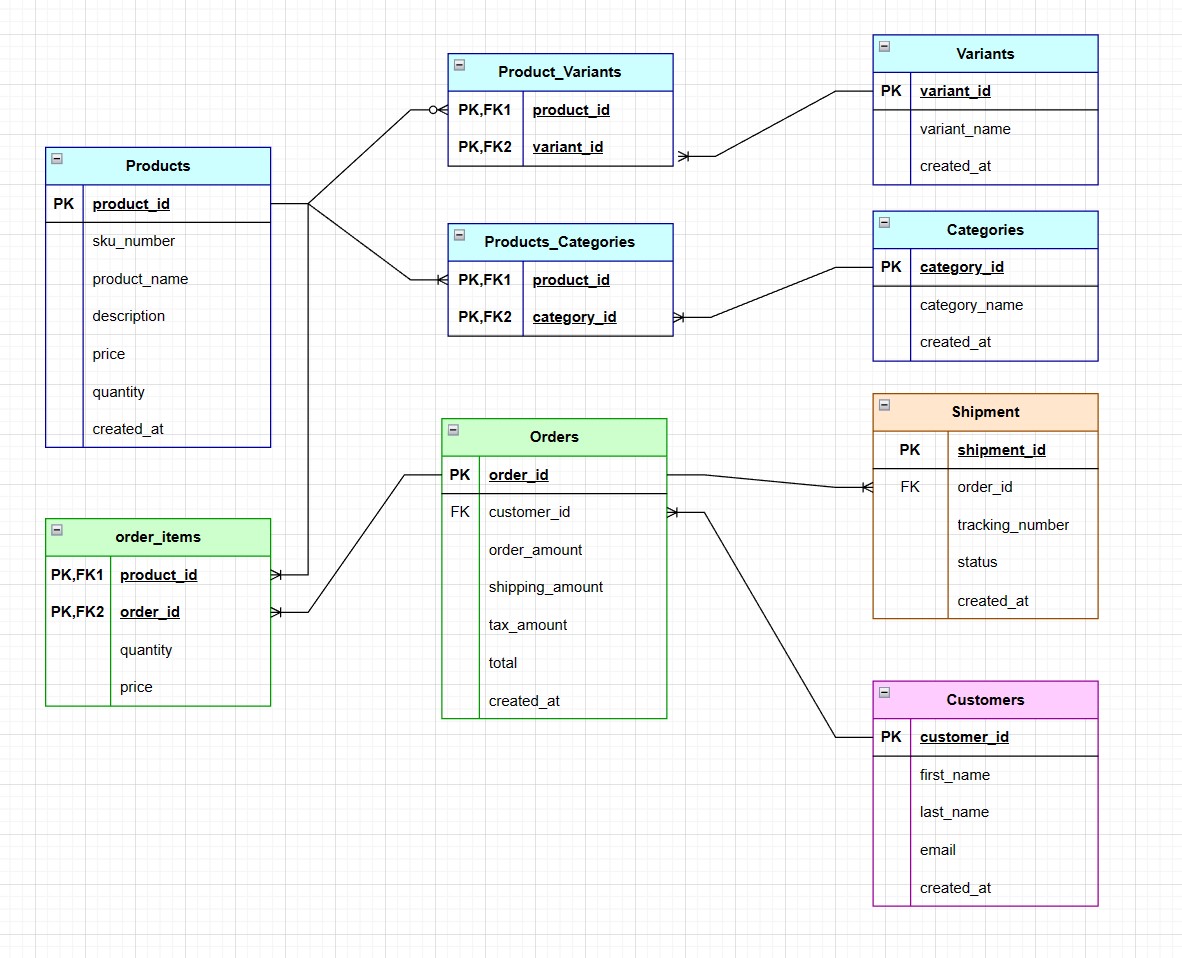
Once the tables were created, I requested ChatGPT to generate the insert scripts. You can find the generated SQL scripts for these prompts on the
GitHub repository.
Based on the tables generated above, create Insert scripts for all the tables.
Ensure the following rules are followed.
1. Remember that the primary key is auto incremented in these tables
with a seed value of 100.
2. Maintain referential integrity.
3. Generate random tracking numbers for shipments.
Note: This prompt needs to be run in continuation to the previous prompt.
Engineering the API and Data Access Layers with FastAPI, Psycopg3, and Pydantic
With the database up and running (verified through pgAdmin), I turned my attention to building APIs that access this database. In my initial prompts, I encountered a minor setback due to a prompt (I created out of ignorance) that explicitly requested the use of Psycopg3 for the data access layer. ChatGPT generated code for Psycopg2 instead and changed the import statement to “import psycopg3,” I took it for its word, and went down the rabbit hole. After some troubleshooting, I realized my mistake and read the documentation to understand the issue. Additionally, I discovered that Psycopg3 stable version was released in October 2021, while ChatGPT was trained on data until September 2021. To resolve the problem, I manually wrote the code for the Psycopg3 connection pool using a helpful solution I found on Stack Overflow.
Once I resolved the issue, I adjusted my prompt and finally arrived at the following prompt, which successfully generated the desired code (check on GitHub):
Your task is to create REST API's using FastAPI and pydantic based on the
steps provided in the text delimited by three stars
Here are some instructions to consider while generating code.
1. Generate the models in a separate file called 'models.py'
2. Assume we already have a 'db.py' file which contains the methods open_pool, close_pool and
exec_query(query, params).This file is already created and you do not need to create this file.
3. Ensure to open pool in startup and close the pool in shutdown of FastAPI.
4. Add Exception handling, especially for relevant HTTP Exceptions.
5. Restrict the query to one query using SQL JOINS instead of multiple queries.
6. Assume the following tables are created with proper referential integrity.
-products (product_id, sku_number, product_name, description, price, quantity)
-variants (variant_id, variant_name)
-products_variants (product_id, variant_id)
-categories (category_id, category_name)
-products_categories (product_id, category_id)
***
1. First, create models for the following types
--Product with fields product_id, sku_number,
product_name, description, price, quantity and
collection of Variants (variant_name)
--Category which has a Name and Text and contains a collection of Products
2. Next, generate the FastAPI code that will have the following capabilities
--Get Product by ID, SKU
--Get Products belonging to a certain category
***
Deploying to Docker
After thoroughly testing the code, I proceeded to write the deployment code. Since I had been testing and verifying different layers, I created separate Dockerfiles (using ChatGPT) for the database layer, the API layer, and the Docker Compose file, allowing me to deploy them together. Here are the respective prompts for each component:
Create Dockerfile for PostgreSQL deployment
Your task is to create a docker file to deploy PostgreSQL and run scripts on it to create tables.
1. Set environment variables.
2. Start PostgreSQL and execute SQL scripts within dockerfile.
After ChatGPT generated the code, I updated it to point to the right script files to execute.
Create Dockerfile for FastAPI deployment
Your task is to create a dockerfile for deploying a FastAPI application.
Here are some instructions to follow
1. App has dependencies on fastapi, uvicorn, pydantic, psycopg[binary,pool], python-dotenv.
These can be encapsulated in a requirements file.
2. The api version is v1.
Finally create the docker compose file to automate deployment of both containers
You are a DevOps Engineer and your task is to create a docker compose file that will be
used to deploy two containers as described below.
Important to note that the dockerfile for both the containers is already created and in respective sub folders.
Use version 3.8 for docker compose
1. The first container is for a database server running on PostgreSQL.
--This container will be called commerceserver.
--Ports to be used are 5432 for both host and container.
2. The second container is for backend services developed using FastAPI.
--This container has a dependency on the database server.
--The environment variables are stored in a .env file.
--This container will be called as commerceapi.
--Ports to be used are 8000 for both host and container.
Key Learnings
Throughout this exercise, I gained valuable insights. Here are the key takeaways from this experience:
- Steep Learning Curve: Despite being relatively new to FastAPI and PostgreSQL, I was able to learn and work with them in less than a week. ChatGPT’s code explanations provided clarity and helped me understand how everything came together.
- Easy Code Generation: Once familiar with the process, code generation became smooth and effortless. Copying and pasting generated code, making necessary adjustments, and incorporating it into the application simplified the development process.
- Limitations with the Free Version: Due to word limits (3000 words) and occasional halts in code generation, I often had to request ChatGPT to “continue generating code.” Although this workaround proved effective, it did present some minor inconveniences.
- Beware of AI Hallucinations: It is essential to cross-check and verify code generated by ChatGPT, as it can occasionally produce inaccuracies or discrepancies. In cases like my experience with Psycopg3, where the generated code did not align with the intended outcome, it is crucial to refer to external sources for confirmation.
- Inconsistent Results: The SQL tables generated by ChatGPT varied slightly each time I ran the prompt. For example, in one instance, the Products table included inventory fields (UnitsInStock, UnitsOnOrder, ReorderLevel), which I would have refactored into a separate referential table. Additionally, the creation of relational tables (e.g., products_categories) was inconsistent. I wonder what the temperature setting is for ChatGPT. Maybe I can override it?
- Instructions May Be Ignored: Despite providing specific instructions, there were instances where ChatGPT overlooked them. For example, in the deployment prompt, even though I explicitly mentioned that the Dockerfile for both the API and database had already been created, ChatGPT incorrectly referenced the Dockerfile for the database only. However, reminding ChatGPT of the oversight in subsequent prompts led to the correction of the generated Docker Compose file.
Conclusion
In conclusion, this exercise was both educational and enjoyable. I gained hands-on experience with FastAPI and PostgreSQL within a short period, thanks to ChatGPT’s assistance. Leveraging code generation streamlined the development process, allowing for efficient backend development. While some limitations and challenges were encountered along the way, the overall outcome proved highly beneficial. By utilizing ChatGPT effectively, you can enhance your development workflow and achieve greater efficiency in your projects.
Feel free to reach out if you have any questions or need further assistance. Happy coding!